AI Investing Machine: How We Orchestrate Work Between Agents (With a Real Example)
- Claude Paugh

- Feb 24
- 4 min read
Modern market analytics demands fast iteration, predictable latency, and strong guardrails. We meet those demands with an agentic architecture that routes user intents to specialized workers, coordinates background jobs, and enforces system limits so no single task overwhelms resources. This post walks through our orchestration model and then shows a concrete example of a production flow.
Why Multi‑Agent Orchestration
Separation of concerns: Each agent is optimized for a narrow capability (e.g., ingestion vs. analytics vs. summarization).
Parallelism without chaos: Work is decomposed and scheduled by a state machine, so heavy tasks don’t block chat UX.
Guardrails by design: Governors and fences prevent runaway costs, long loops, and cache explosions.
Observability: Every agent publishes a heartbeat and state transitions so ops can answer “what is running and why?”
Orchestration at a Glance
Chat Gateway (orchestrator): Parses a message, classifies intent, extracts identifiers/filters, and decides the next action.
Decision Tree: A rules engine that maps phrases and keywords to specific tools/actions (e.g., technical analysis, financial statements, searches).
Background Agents: Long‑running workers for ingestion, aggregation, syncing, and heavy queries, each with its own state machine and Redis outbox.
Data Plane: External data sources (APIs), Postgres, Redis cache, Neo4j, and file/object stores.- Guardrails: Turn limits, rate limits, depth limits, and cooldowns across subsystems.

From Message to Action: The Decision Tree
When a user asks something, the gateway normalizes and classifies the request, then applies a decision tree to choose an action.
Examples from `orchestration_rules.json`:
“technical analysis of AAPL” → `technical_analysis`
“income statement for MSFT” → `get_income_statement` (with overrides for balance sheet, cash flow, estimates)
“run market scan” → background job orchestration
“search for company by name” → `search_by_name`

Heuristics can override or refine routes (e.g., choosing correlations instead of a generic TA chart if the user mentions “correlation” or “deviation”). This lets us stay robust even if the LLM’s first guess is imperfect.
Agents and Their Roles
Each agent has a minimal, explicit contract: inputs, outputs, states, and back‑pressure mechanisms.
Each agent has a minimal, explicit contract: inputs, outputs, states, and back‑pressure mechanisms.
Sync Agent
Purpose: Replicate selected Postgres views to Redis for low‑latency reads.
States: `IDLE → PROCESSING → SYNCING → SUCCESS/FAILURE`.
Observability: Status and last result surfaced via the gateway.
Aggregation Agent
Purpose: Pre‑compute expensive graph/db queries and summaries.
States: `IDLE → IDENTIFYING → AGGREGATING → SUCCESS/FAILURE`.
UX optimization: If a cached result exists, the gateway answers without extra back‑and‑forth.
Ingestion Agent
Purpose: Discover, fetch, and store new data (user‑triggered or scheduled) with strict discovery/depth limits.
States: `IDLE → DISCOVERING → INGESTING → SUCCESS/FAILURE`.
Query Agent
Purpose: Offload heavy DB queries and serialization to a worker pool with per‑source concurrency limits.
Benefit: The chat thread stays responsive while background workers stream results back via Redis.
Guardrails That Keep The System Healthy
Turn Governor: Caps tool executions per user turn (default 10) to prevent infinite loops.
Ingestion Fence: Caps web lookup depth and discovery counts (e.g., 50 per user task) to prevent crawlers from running away.
Sync Governor: Caps rows pulled per Postgres view (e.g., 100k) to protect Redis memory.
Cooldowns: Mandatory pauses between heavy jobs so spikes don’t collapse external APIs/databases.
These aren’t afterthoughts—they’re first‑class orchestration features that create predictable costs and latency.
Example Walk‑Through: Index Quotes Refresh Flow
A representative production task is refreshing global index quotes and caching them for fast UI/API responses. The flow is implemented with Prefect tasks and integrates with our TA service and Redis cache.
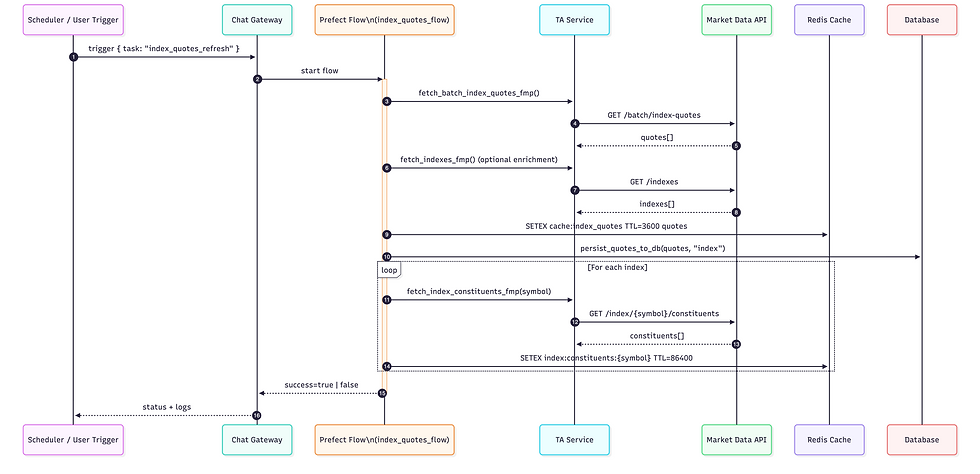
How it works end‑to‑end:
Trigger - The gateway or a scheduler triggers the “Index Quotes Update Flow.”
The trigger includes a light payload such as `{ task: "index_quotes_refresh" }`.
Fetch
The task queries a market data API through the TA service (`ta_service.fetch_batch_index_quotes_fmp()`).
Optionally fetches the official index list to enrich symbols with name/currency.
Cache + Persist
Results are cached in Redis with a TTL (e.g., 1 hour) for fast reads by the UI and APIs.
Quotes are written to the database via `persist_quotes_to_db(quotes, "index")`.
For each index, the task may also fetch constituents and cache them for downstream analytics (e.g., world P/E by market).
Observability & Exit
The flow logs counts and error messages; success/failure is surfaced in the gateway’s system status endpoints.
If an upstream error occurs, the flow returns `False` and is retried later based on schedule/policy.
Why this pattern works:
The chat UX never stalls; users always see a recent snapshot thanks to cache.- Background work is bounded (rate‑limited, TTL’d) and observable.- Downstream features (e.g., sector summaries, P/E maps) read from a consistent cache.
Another Common Flow: News Ingestion (High‑Level)
Triggered by: “start news ingestion” or a scheduler.
Steps:
1) Discover new news items within configured sources/categories.
2) Ingest and normalize items, apply basic deduplication.
3) Persist metadata and cache recent headlines for UI.
Guardrails: Depth/quantity caps per run, cooldowns between source fetches.
Result: The chat/UI can instantly surface fresh stories without re‑hitting external sources on every request.
Routing, Caching, and Short‑Circuiting
If a user asks for information that exists in cache (e.g., a summary or a recent quote set), the gateway answers immediately.
If a result is missing or stale, the gateway can:
Trigger a background job and return “working, will update,” or
Defer to the user for confirmation (for costlier operations) based on the decision tree.
Heavy queries are offloaded to the Query Agent to avoid blocking the chat thread.
Operations: What We Monitor
Agent heartbeats and last state transition times (per agent).
Queue depths and outbox sizes.
Cache hit/miss ratios and payload sizes.
Decision tree routing stats (which tools fire, how often, and where overrides apply).
Error rates and retry outcomes per background flow.
Operational visibility is built into the gateway endpoints (see `get_system_status`, `get_agent_logs`, and related functions in `chat_gateway/app.py`).
Takeaways
- A small set of specialized agents, a simple decision tree, and strict guardrails go a long way toward reliable AI‑assisted analytics.
- The orchestration layer makes cost/latency predictable and the UX responsive.
- Clear state machines and monitoring keep operations boring—in the best possible way.
If you’d like a deeper dive into any component (e.g., ingestion fences, the decision rules, or the query worker pool), let us know and we’ll follow up with a focused post.


