Apache Iceberg and Pandas Analytics: Part II
- Claude Paugh

- May 9, 2025
- 14 min read
Updated: Aug 18, 2025
As I had indicated in Part I, I had built some basic examples with PyIceberg and Python to learn more, and exercise some of the functionality it offers. I started by using data that I collect from time-to-time, for securities, mostly common stocks, and various twelve-month key metrics and analyst forecasts. This is an extension to my SEC filings collection that I have a running series of articles on. I use this particular data to build out details for securities in my Neo4j graph representation.
Acquiring Source Data
I have a subscription with FMP(Financial Modeling Prep), which has a good amount of securities data available via their API at a reasonable subscription price. I have used a similar pattern with the data retrieval, detailed in the ETF, Mutual Fund Portfolio Holdings posts. Which is basically, having a set of data that contains lists of identifiers(Ticker symbols, ISIN, CUSIP, etc.) and I iterate through the list then make requests against a source of data. I track the response and update a status for success/failure on each request. Initially it was SEC filing data, but in this case its the FMP API urls. I have pasted the script for FMP API requests below.
import json
import time
import urllib3
import uuid
from couchbase.auth import PasswordAuthenticator
from couchbase.cluster import Cluster
from couchbase.options import ClusterOptions, ClusterTimeoutOptions
from datetime import datetime, timedelta
from fmp_token import fmb_api_token
from ref_data.connect_util import getconn
import env.creds as creds
import env.uri as uri
endpoint = uri.couchbase_server
auth = PasswordAuthenticator(creds.CDC_USER, creds.CDC_PASS)
timeout_opts = ClusterTimeoutOptions(
kv_timeout=timedelta(seconds=10),
connect_timeout=timedelta(seconds=10),
query_timeout=timedelta(seconds=120),
)
cluster = Cluster(
"couchbase://{}".format(endpoint),
ClusterOptions(auth, timeout_options=timeout_opts),
)
def getUrlList():
symbol = "None"
url_request_list = []
url_request_list.append(
f"https://financialmodelingprep.com/api/v3/profile/{symbol}?apikey={fmb_api_token}"
)
url_request_list.append(
f"https://financialmodelingprep.com/api/v4/company-outlook?symbol={symbol}&apikey={fmb_api_token}"
)
url_request_list.append(
f"https://financialmodelingprep.com/api/v4/company-notes?symbol={symbol}&apikey={fmb_api_token}"
)
url_request_list.append(
f"https://financialmodelingprep.com/api/v3/ratios-ttm/{symbol}?apikey={fmb_api_token}"
)
url_request_list.append(
f"https://financialmodelingprep.com/api/v4/score?symbol={symbol}&apikey={fmb_api_token}"
)
url_request_list.append(
f"https://financialmodelingprep.com/api/v3/key-metrics-ttm/{symbol}?limit=1&apikey={fmb_api_token}"
)
url_request_list.append(
f"https://financialmodelingprep.com/api/v3/financial-growth/{symbol}?limit=30&apikey={fmb_api_token}"
)
return url_request_list
def acquireUrlData(url):
http = urllib3.PoolManager()
req_url = f"{url}"
response = http.request("GET", req_url)
if response.status == 200:
data_payload = json.loads(response.data.decode("utf-8"))
time.sleep(0.25)
return data_payload
if __name__ == "__main__":
conn, conn_r = getconn()
cur = conn_r.cursor()
result = cur.execute(
"SELECT distinct symbol FROM inbd_raw.reference_symbols where "
"acquire_fmp_inst_details = false and asset_type not in ('et', 'mf', 'ut')"
)
result_list = cur.fetchall()
for row in result_list:
symbol = row[0]
# print(row)
processDT = datetime.today().strftime("%Y-%m-%d %H:%M:%S")
bucket = cluster.bucket("common-reference")
scope = bucket.scope("security-reference")
url_list = getUrlList()
doc: dict = {}
if symbol != "":
for url in url_list:
url = url.replace("None", symbol)
if "profile" in url:
data_payload = acquireUrlData(url)
collection = scope.collection("Overview")
for doc in data_payload:
doc.update(doc)
doc.update({"AsOfDt": processDT})
collection.insert(str(uuid.uuid4()), doc)
print(f"Document Profile posted for Instrument {symbol}")
time.sleep(0.25)
if "outlook" in url:
data_payload = acquireUrlData(url)
collection = scope.collection("Forecast-Outlook")
data_payload.update({"AsOfDt": processDT})
collection.insert(str(uuid.uuid4()), data_payload)
print(f"Document Company-Outlook posted for Instrument {symbol}")
time.sleep(0.25)
if "notes" in url:
data_payload = acquireUrlData(url)
if data_payload:
collection = scope.collection("Company-Notes")
for row in data_payload:
row.update({"AsOfDt": processDT})
collection.insert(str(uuid.uuid4()), row)
print(
f"Document Company-Notes posted for Instrument {symbol}"
)
time.sleep(0.25)
if "ratios-ttm" in url:
data_payload = acquireUrlData(url)
collection = scope.collection("TTM-Ratios")
for row in data_payload:
row.update({"AsOfDt": processDT})
row.update({"symbol": symbol})
collection.insert(str(uuid.uuid4()), row)
print(f"Document Ratios-TTM posted for Instrument {symbol}")
time.sleep(0.25)
if "score" in url:
data_payload = acquireUrlData(url)
if data_payload:
collection = scope.collection("P-Score")
for row in data_payload:
row.update({"AsOfDt": processDT})
collection.insert(str(uuid.uuid4()), row)
print(f"Document P-Score posted for Instrument {symbol}")
time.sleep(0.25)
if "key-metrics" in url:
data_payload = acquireUrlData(url)
if data_payload:
collection = scope.collection("Key-Metrics-TTM")
for row in data_payload:
row.update({"AsOfDt": processDT})
row.update({"symbol": symbol})
collection.insert(str(uuid.uuid4()), row)
print(f"Document Key-Metrics posted for Instrument {symbol}")
time.sleep(0.25)
if "financial-growth" in url:
data_payload = acquireUrlData(url)
if data_payload:
collection = scope.collection("Financial-Growth")
for row in data_payload:
row.update({"AsOfDt": processDT})
collection.insert(str(uuid.uuid4()), row)
print(
f"Document Financial-Growth posted for Instrument {symbol}"
)
time.sleep(0.25)
cur_upd = conn_r.cursor()
upd_str = (
f"UPDATE inbd_raw.reference_symbols SET acquire_fmp_inst_details = true, acquire_fmp_inst_ts = current_timestamp "
f"where symbol = '{symbol}'")
cur_upd.execute(upd_str)
conn_r.commit()
cur_upd.close()
print(f"Update table reference_symbols for {symbol}")
As you can tell from the Python script, a table in a local PostgreSQL database, contains stock ticker symbols and some tracking information, it provides input to the requests. Approximately 70,000 ticker symbols are in the table, and they are retrieved via an SQL statement to start. Each symbol and API token is then passed to each url of the seven FMP API urls, and the request is made. The payload and/or status is returned, and decoded to JSON.
The JSON is parsed and sections are separated and then inserted into a Couchbase database namespace, bucket and targeted collection. Collections are below to the left.

Each collection has its own document schema defined, and is indexed to optimize for retrieval.
The documents have an additional field, AsOfDate, which is the load date, in order to keep the multiple versions of documents to trend and compare over time.

Data can then be retrieved or extracted via Couchbase SQL++, which is a SQL like syntax that you can use to query the collections within the buckets and scopes.
I detailed previously in my financial data series of posts, that I usually use Jetbrains DataGrip for querying Couchbase, as they supply a driver to connect to the database.
There were three areas that I wanted to extract for this particular example, and they were basically
1. Company descriptive data
2. Twelve month ratios
3. Forecasted financial data with some history
Target Data Retrieval
I constructed three SQL++ scripts that are in the expandable list below. The first is to get basic company reference information, the second gets twelve months of key metrics, and the third retrieves forecasts for company financials.
company-reference
select AsOfDt as AsOfDate,
companyName as CompanyName,
description as Description,
symbol as Ticker,
isin as ISIN,
cusip as CUSIP,
exchange as Exchange,
exchangeShortName as ExchangeShortName,
ROUND(volAvg, 6) as AverageVolume,
industry as Industry,
ipoDate as IPO_Date,
country as Country,
currency as Currency,
sector as Sector,
ceo as CEO,
cik as CIK,
city as City,
state as State,
zip as ZipCode,
website as Website,
isAdr as ADR,
isEtf as isETF,
isFund as isFund,
fullTimeEmployees as Employees,
ROUND(dcf, 6) as Discounted_Cash_Flow,
ROUND(dcfDiff, 6) as Discounted_Cash_Flow_Diff,
ROUND(beta, 6) as Beta,
address as Address
from `common-reference`.`security-reference`.`Overview`where date_trunc_str(AsOfDt, 'day') >= '2025-04-16' and isActivelyTrading = true
order by date_trunc_str(AsOfDt, 'day') >= '2025-04-16';key-metrics-ttm
SELECT DISTINCT km.AsOfDt AS AsOfDate,
km.symbol as Ticker,
ROUND(km.capexToOperatingCashFlowTTM*100, 6) as Capex_To_Operating_CashFlow_PCT,
ROUND(km.currentRatioTTM, 6) as Current_Ratio,
ROUND(km.capexPerShareTTM, 6) as Capex_Per_Share,
ROUND(km.capexToRevenueTTM*100, 6) as Capex_To_Revenue_PCT,
ROUND(km.cashPerShareTTM, 6) as Cash_Per_Share,
ROUND(km.debtToAssetsTTM*100, 6) as Debt_To_Assets_PCT,
ROUND(km.debtToEquityTTM*100, 6) as Debt_To_Equity_PCT,
ROUND(km.debtToMarketCapTTM*100, 6) as Debt_To_Market_Cap_PCT,
ROUND(km.daysOfInventoryOnHandTTM, 6) as Days_Of_Inventory_OnHand,
ROUND(km.dividendPerShareTTM, 6) as Dividend_Per_Share,
ROUND(km.dividendYieldTTM*100, 6) as Dividend_Yield_PCT,
ROUND(km.freeCashFlowPerShareTTM, 6) as Free_Cash_Flow_Per_Share,
ROUND(km.freeCashFlowYieldTTM*100, 6) as Free_Cash_Flow_Yield_PCT,
ROUND(km.intangiblesToTotalAssetsTTM, 6) as Intangibles_To_TotalAssets,
ROUND(km.netCurrentAssetValueTTM, 6) as Net_Current_Assets,
ROUND(km.netDebtToEBITDATTM, 6) as Net_Debt_To_EBITDA,
ROUND(km.netIncomePerShareTTM, 6) as Net_Income_Per_Share,
ROUND(km.operatingCashFlowPerShareTTM, 6) as Operating_Cash_Flow_Per_Share,
ROUND(km.pbRatioTTM, 6) as Price_To_Book,
ROUND(km.peRatioTTM, 6) as Price_To_Earnings,
ROUND(km.pfcRationTTM, 6) as Price_To_Free_Cash_Flow,
ROUND(km.pocfrationTTM, 6) as Price_To_Operating_Cash_Flow,
ROUND(km.researchAndDevelopementToRevenueTTM, 6) as R_And_D_ToRevenue,
ROUND(km.revenuePerShareTTM, 6) as Revenue_Per_Share,
ROUND(km.roeTTM*100, 6) as Return_On_Equity_PCT,
ROUND(km.roicTTM*100, 6) as Return_On_Invested_Capital_PCT,
ROUND(km.shareholdersEquityPerShareTTM, 6) as Shareholders_Equity_Per_Share,
ROUND(km.stockBasedCompensationToRevenueTTM, 6) as Stock_Compensation_To_Revenue,
ROUND(km.tangibleAssetValueTTM, 6) as Tangible_Asset_Value,
ROUND(km.tangibleBookValuePerShareTTM, 6) as Tangible_Book_Value_Per_Share,
ROUND(km.workingCapitalTTM, 6) as Working_Capital_Local_Currency,
ROUND(tr.assetTurnoverTTM, 6) as Asset_Turnover,
ROUND(tr.capitalExpenditureCoverageRatioTTM, 6) as Capex_To_Coverage_Ratio,
ROUND(tr.cashConversionCycleTTM, 6) as Cash_Conversion_Cycle,
ROUND(tr.ebitPerRevenueTTM, 6) as EBIT_Per_Revenue,
ROUND(tr.effectiveTaxRateTTM*100, 6) as Effective_Tax_Rate_PCT,
ROUND(tr.enterpriseValueMultipleTTM, 6) as Enterprise_Value_Multiple,
ROUND(tr.grossProfitMarginTTM, 6) as Gross_Profit_Margin,
ROUND(tr.interestCoverageTTM, 6) as Interest_Coverage,
ROUND(tr.longTermDebtToCapitalizationTTM, 6) as Long_Term_Debt_To_Capitalization,
ROUND(tr.netProfitMarginTTM*100, 6) as Net_Profit_Margin_PCT,
ROUND(tr.operatingCashFlowSalesRatioTTM, 6) as Operating_CashFlow_To_Sales_Ratio,
ROUND(tr.operatingCycleTTM, 6) as Operating_Cycle,
ROUND(tr.operatingProfitMarginTTM, 6) as Operating_Profit_Margin,
ROUND(tr.payablesTurnoverTTM, 6) as Payables_Turnover,
ROUND(tr.pretaxProfitMarginTTM*100, 6) as Pre_Tax_Profit_Margin_PCT,
ROUND(tr.priceFairValueTTM, 6) as Price_To_Fair_Value,
ROUND(tr.priceToSalesRatioTTM, 6) as Price_To_Sales_Ratio,
ROUND(tr.quickRatioTTM, 6) as Quick_Ratio,
ROUND(tr.receivablesTurnoverTTM, 6) as Receivables_Turnover,
ROUND(tr.returnOnCapitalEmployedTTM*100, 6) as Return_On_Capital_Employed_PCT,
ROUND(tr.totalDebtToCapitalizationTTM*100, 6) as Total_Debt_To_Capitalization_PCTFROM `common-reference`.`security-reference`.`Overview` ov INNER JOIN `common-reference`.`security-reference`.`Key-Metrics-TTM` km ON ov.symbol = km.symbol AND date_trunc_str(ov.AsOfDt, 'day') = date_trunc_str(km.AsOfDt, 'day') LEFT JOIN `common-reference`.`security-reference`.`TTM-Ratios` tr ON ov.symbol = tr.symbol AND date_trunc_str(ov.AsOfDt, 'day') = date_trunc_str(tr.AsOfDt, 'day') WHERE date_trunc_str(km.AsOfDt, 'day') >= '2025-04-16' and ov.isActivelyTrading = trueORDER BY date_trunc_str(km.AsOfDt, 'day') >= '2025-04-16';financial-growth-projected
SELECT DISTINCT fg.AsOfDt AS AsOfDate,
fg.symbol as Ticker,
TONUMBER(fg.calendarYear) as CalendarYear,
coalesce(fg.date, '1900-01-01') as EstimateDate,
coalesce(ROUND(fg.debtGrowth*100, 6), tonumber(0)) as Debt_Growth_PCT,
ROUND(fg.dividendsperShareGrowth, 6) as Dividend_Per_Share_Growth,
coalesce(ROUND(fg.dividendYieldPCT*100, 6), tonumber(0)) as Dividend_Yield_PCT,
coalesce(ROUND(fg.ebitdaGrowth*100, 6), tonumber(0)) as EBITDA_Growth_PCT,
coalesce(ROUND(fg.ebitGrowth*100, 6), tonumber(0)) as EBIT_Growth_PCT,
ROUND(fg.epsdilutedGrowth*100, 6) as EPS_Diluted_Growth_PCT,
coalesce(ROUND(fg.epsGrowth*100, 6), tonumber(0)) as EPS_Growth_PCT,
ROUND(fg.fiveYDividendperShareGrowthPerShare, 6) as Five_Year_Dividend_Per_Share_Growth,
ROUND(fg.fiveYNetIncomeGrowthPerShare, 6) as Five_Year_Net_Income_Growth_Per_Share,
ROUND(fg.fiveYOperatingCFGrowthPerShare, 6) as Five_Year_Operating_CashFlow_Growth_Per_Share,
ROUND(fg.fiveYRevenueGrowthPerShare, 6) as Five_Year_Revenue_Growth_Per_Share,
ROUND(fg.fiveYShareholdersEquityGrowthPerShare, 6) as Five_Year_Shareholders_Equity_Growth_Per_Share,
ROUND(fg.freeCashFlowGrowth*100, 6) as Free_CashFlow_Growth_PCT,
coalesce(ROUND(fg.freeCashFlowPerShare, 6), tonumber(0)) as Free_CashFlow_Per_Share,
ROUND(fg.grossProfitGrowth*100, 6) as Gross_Profit_Growth_PCT,
coalesce(ROUND(fg.grossProfitMargin, 6), tonumber(0)) as Gross_Profit_Margin,
coalesce(ROUND(fg.cashPerShare, 6), tonumber(0)) as Cash_Per_Share,
coalesce(ROUND(fg.cashConversionCycle, 6), tonumber(0)) as Cash_Conversion_Cycle,
coalesce(ROUND(fg.currentRatio, 6), tonumber(0)) as Current_Ratio,
coalesce(ROUND(fg.debtToEquity, 6), tonumber(0)) as Debt_To_Equity,
coalesce(ROUND(fg.debtToAsset, 6), tonumber(0)) as Debt_To_Asset,
coalesce(ROUND(fg.debtToEBITDA, 6), tonumber(0)) as Debt_To_EBITDA,
coalesce(ROUND(fg.debtToEBIT, 6), tonumber(0)) as Debt_To_EBIT,
coalesce(ROUND(fg.debtToOperatingCashFlow, 6), tonumber(0)) as Debt_To_Operating_CashFlow,
coalesce(ROUND(fg.debtToRevenue, 6), tonumber(0)) as Debt_To_Revenue,
coalesce(ROUND(fg.debtToShareholdersEquity, 6), tonumber(0)) as Debt_To_Shareholders_Equity,
coalesce(ROUND(fg.equityToAsset, 6), tonumber(0)) as Equity_To_Asset,
ROUND(fg.inventoryGrowth*100, 6) as Inventory_Growth_PCT,
ROUND(fg.netIncomeGrowth*100, 6) as Net_Income_Growth_PCT,
coalesce(ROUND(fg.netIncomePerShare, 6), tonumber(0)) as Net_Income_Per_Share,
ROUND(fg.operatingCashFlowGrowth*100, 6) as Operating_CashFlow_Growth_PCT,
coalesce(ROUND(fg.operatingCashFlowPerShare, 6), tonumber(0)) as Operating_CashFlow_Per_Share,
ROUND(fg.operatingIncomeGrowth*100, 6) as Operating_Income_Growth_PCT,
coalesce(ROUND(fg.revenueGrowth*100, 6), tonumber(0)) as Revenue_Growth_PCT,
ROUND(fg.rdexpenseGrowth*100, 6) as RD_Expense_Growth_PCT,
fg.period as Period,
ROUND(fg.receivablesGrowth*100, 6) as Receivables_Growth_PCT,
coalesce(ROUND(fg.receivablesTurnover, 6),tonumber(0) ) as Receivables_Turnover,
ROUND(fg.sgaexpensesGrowth*100, 6) as SGA_Expense_Growth_PCT,
ROUND(fg.threeYShareholdersEquityGrowthPerShare, 6) as Three_Year_Shareholders_Equity_Growth_Per_Share,
ROUND(fg.threeYRevenueGrowthPerShare, 6) as Three_Year_Revenue_Growth_Per_Share,
ROUND(fg.threeYOperatingCFGrowthPerShare, 6) as Three_Year_Operating_CashFlow_Growth_Per_Share,
ROUND(fg.threeYNetIncomeGrowthPerShare, 6) as Three_Year_Net_Income_Growth_Per_Share,
ROUND(fg.threeYDividendperShareGrowthPerShare, 6) as Three_Year_Dividend_Per_Share_Growth,
ROUND(fg.tenYShareholdersEquityGrowthPerShare, 6) as Ten_Year_Shareholders_Equity_Growth_Per_Share,
ROUND(fg.tenYRevenueGrowthPerShare, 6) as Ten_Year_Revenue_Growth_Per_Share,
ROUND(fg.tenYOperatingCFGrowthPerShare, 6) as Ten_Year_Operating_CashFlow_Growth_Per_Share,
ROUND(fg.tenYNetIncomeGrowthPerShare, 6) as Ten_Year_Net_Income_Growth_Per_Share,
ROUND(fg.tenYDividendperShareGrowthPerShare, 6) as Ten_Year_Dividend_Per_Share_Growth
FROM `common-reference`.`security-reference`.`Overview` ov INNER JOIN `common-reference`.`security-reference`.`Financial-Growth` fg
ON ov.symbol = fg.symbol AND date_trunc_str(ov.AsOfDt, 'day') = date_trunc_str(fg.AsOfDt, 'day')
WHERE date_trunc_str(ov.AsOfDt, 'day') >= '2025-04-16' and ov.isActivelyTrading = true and TONUMBER(fg.calendarYear) = 2016
ORDER BY date_trunc_str(ov.AsOfDt, 'day');
Like I had done previously, I executed each of the above scripts in DataGrip and then exported the results to pipe-delimited files with headers. So now I had my source data that I wanted to use for Apache Iceberg tables.
Starting with PyIceberg Configuration
I started by reading the PyIceberg documentation, and reading through the "Getting Started" and "Configuration" sections. I also went back to the project source docs to get more familiar with some overall concepts and implementations with other languages and tools.
Fortunately, I had previously worked with Apache Spark, Apache AVRO and Apache Arrow (separately) on projects, so I already had some knowledge of those. But I thought it was important to read the docs on PyIceberg, so I can get the context on how they were being used in this case. It can be a lot to read, but I tend to like to look laterally when I start something new to get more context.
I had decided that I would use a PostgreSQL database to store the catalog tables; no particular reason other than I think it might not be a common deployment pattern. Instead of creating a YAML file as was suggested, I decided to put my configuration in JSON format in a Python file:
cat = {
"catalog": {
"default": {
"type": "sql",
"uri": "postgresql+psycopg2://iceb_cat_usr:########@10.0.0.30:5439/ib_cat",
"warehouse": "/Volumes/ExtShield/warehouse",
"write.metadata.previous-versions.max": 5,
"write.data.path": "/Volumes/ExtShield/warehouse",
"commit.manifest-merge.enabled": "True",
"py-io-impl": "pyiceberg.io.pyarrow.PyArrowFileIO"
},
},
}Iceberg Catalog Tables in PostgreSQL

I then created a get_catalog() function that I could use with other Python code, so I didn't have to repeat it every time:
get_catalog.py
from pyiceberg.catalog import load_catalog
import ipyiceberg as ipg
# Get keys from a dictionary
props = ipg.cat["catalog"]["default"]
type = props["type"]
uri = props["uri"]
warehouse = props["warehouse"]
py_io = props["py-io-impl"]
def get_catalog():
catalog = load_catalog(
name="sqlcat",
**{"uri": uri,
"type": type,
"warehouse": warehouse,
"py-io-impl": py_io}
)
return catalog
As I indicated above, I was going to use three data sets which I was exporting from my Couchbase warehouse to load into Iceberg, so I went about creating two scripts. One for the schema definition and the other to automate the drop/creation of the tables.
I had already created the namespace "docs" as part of a tutorial on Iceberg, so I continued to use that as the namespace. The tables are defined by the schema_df.py script below. With the first table I used keywords in the definition, the second two I used just positional values.
schema_def.py
from pyiceberg.schema import Schema
from pyiceberg.types import NestedField, StringType, DoubleType, DateType, BooleanType, IntegerType, TimestampType
# First table includes keywords for schema definition; the remaining two tables are positional
company_schema = Schema(
fields=(NestedField(field_id=1, name="AsOfDate", field_type=TimestampType(), required=True),
NestedField(field_id=2, name="Ticker", field_type=StringType(), required=True),
NestedField(field_id=3, name="CompanyName", field_type=StringType(), required=False),
NestedField(field_id=4, name="CIK", field_type=StringType(), required=False),
NestedField(field_id=5, name="ISIN", field_type=StringType(), required=False),
NestedField(field_id=6, name="CUSIP", field_type=StringType(), required=False),
NestedField(field_id=7, name="Description", field_type=StringType(), required=False),
NestedField(field_id=8, name="Exchange", field_type=StringType(), required=False),
NestedField(field_id=9, name="ExchangeShortName", field_type=StringType(), required=False),
NestedField(field_id=10, name="Sector", field_type=StringType(), required=False),
NestedField(field_id=11, name="Country", field_type=StringType(), required=False),
NestedField(field_id=12, name="Currency", field_type=StringType(), required=False),
NestedField(field_id=13, name="City", field_type=StringType(), required=False),
NestedField(field_id=14, name="State", field_type=StringType(), required=False),
NestedField(field_id=15, name="Address", field_type=StringType(), required=False),
NestedField(field_id=16, name="Employees", field_type=StringType(), required=False),
NestedField(field_id=17, name="CEO", field_type=StringType(), required=False),
NestedField(field_id=18, name="Website", field_type=StringType(), required=False),
NestedField(field_id=19, name="ZipCode", field_type=StringType(), required=False),
NestedField(field_id=20, name="ADR", field_type=BooleanType(), required=False),
NestedField(field_id=21, name="isFund", field_type=BooleanType(), required=False),
NestedField(field_id=22, name="isETF", field_type=BooleanType(), required=False),
NestedField(field_id=23, name="AverageVolume", field_type=DoubleType(), required=False),
NestedField(field_id=24, name="Beta", field_type=DoubleType(), required=False),
NestedField(field_id=25, name="Discounted_Cash_Flow", field_type=DoubleType(), required=False),
NestedField(field_id=26, name="Discounted_Cash_Flow_Diff", field_type=DoubleType(), required=False),
NestedField(field_id=27, name="IPO_Date", field_type=DateType(), required=False),
NestedField(field_id=28, name="Industry", field_type=StringType(), required=False),
))
ratio_schema_ttm = Schema(
fields=(NestedField(1, "AsOfDate", TimestampType(), required=True),
NestedField(2,"Ticker", StringType(), required=True),
NestedField(3, "Asset_Turnover", DoubleType(), required=False),
NestedField(4, "Capex_Per_Share", DoubleType(), required=False),
NestedField(5, "Capex_To_Coverage_Ratio", DoubleType(), required=False),
NestedField(6, "Capex_To_Operating_CashFlow_PCT", DoubleType(), required=False),
NestedField(7, "Capex_To_Revenue_PCT", DoubleType(), required=False),
NestedField(8, "Cash_Conversion_Cycle", DoubleType(), required=False),
NestedField(9, "Cash_Per_Share", DoubleType(), required=False),
NestedField(10, "Current_Ratio", DoubleType(), required=False),
NestedField(11, "Days_Of_Inventory_OnHand", DoubleType(), required=False),
NestedField(12, "Debt_To_Assets_PCT", DoubleType(), required=False),
NestedField(13, "Debt_To_Equity_PCT", DoubleType(), required=False),
NestedField(14, "Debt_To_Market_Cap_PCT", DoubleType(), required=False),
NestedField(15, "Dividend_Per_Share", DoubleType(), required=False),
NestedField(16, "Dividend_Yield_PCT", DoubleType(), required=False),
NestedField(17, "EBIT_Per_Revenue", DoubleType(), required=False),
NestedField(18, "Effective_Tax_Rate_PCT", DoubleType(), required=False),
NestedField(19, "Enterprise_Value_Multiple", DoubleType(), required=False),
NestedField(20, "Free_Cash_Flow_Per_Share", DoubleType(), required=False),
NestedField(21, "Free_Cash_Flow_Yield_PCT", DoubleType(), required=False),
NestedField(22, "Gross_Profit_Margin", DoubleType(), required=False),
NestedField(23, "Gross_Profit_Growth_PCT", DoubleType(), required=False),
NestedField(24, "Intangibles_To_TotalAssets", DoubleType(), required=False),
NestedField(25, "Interest_Coverage", DoubleType(), required=False),
NestedField(26, "Long_Term_Debt_To_Capitalization", DoubleType(), required=False),
NestedField(27, "Net_Current_Assets", DoubleType(), required=False),
NestedField(28, "Net_Debt_To_EBITDA", DoubleType(), required=False),
NestedField(29, "Net_Income_Per_Share", DoubleType(), required=False),
NestedField(30, "Net_Profit_Margin_PCT", DoubleType(), required=False),
NestedField(31, "Operating_CashFlow_To_Sales_Ratio", DoubleType(), required=False),
NestedField(32, "Operating_Cash_Flow_Per_Share", DoubleType(), required=False),
NestedField(33, "Operating_Cycle", DoubleType(), required=False),
NestedField(34, "Operating_Profit_Margin", DoubleType(), required=False),
NestedField(35, "Payables_Turnover", DoubleType(), required=False),
NestedField(36, "Pre_Tax_Profit_Margin_PCT", DoubleType(), required=False),
NestedField(37, "Price_To_Book", DoubleType(), required=False),
NestedField(38, "Price_To_Earnings", DoubleType(), required=False),
NestedField(39, "Price_To_Fair_Value", DoubleType(), required=False),
NestedField(40, "Price_To_Sales_Ratio", DoubleType(), required=False),
NestedField(41, "Quick_Ratio", DoubleType(), required=False),
NestedField(42, "R_And_D_ToRevenue", DoubleType(), required=False),
NestedField(43, "Receivables_Turnover", DoubleType(), required=False),
NestedField(44, "Return_On_Capital_Employed_PCT", DoubleType(), required=False),
NestedField(45, "Return_On_Equity_PCT", DoubleType(), required=False),
NestedField(46, "Return_On_Invested_Capital_PCT", DoubleType(), required=False),
NestedField(47, "Revenue_Per_Share", DoubleType(), required=False),
NestedField(48, "Shareholders_Equity_Per_Share", DoubleType(), required=False),
NestedField(49, "Stock_Compensation_To_Revenue", DoubleType(), required=False),
NestedField(50, "Tangible_Asset_Value", DoubleType(), required=False),
NestedField(51, "Tangible_Book_Value_Per_Share", DoubleType(), required=False),
NestedField(52,"Total_Debt_To_Capitalization_PCT", DoubleType(), required=False),
NestedField(53,"Working_Capital_Local_Currency", DoubleType(), required=False),
))
forecast_schema = Schema(
fields=(NestedField(1, "AsOfDate", TimestampType(), required=True),
NestedField(2, "Ticker", StringType(), required=True),
NestedField(3, "CalendarYear", IntegerType(), required=True),
NestedField(4, "EstimateDate", DateType(), required=False),
NestedField(5, "Debt_Growth_PCT", DoubleType(), required=False),
NestedField(6, "Dividend_Per_Share_Growth", DoubleType(), required=False),
NestedField(7, "Dividend_Yield_PCT", DoubleType(), required=False),
NestedField(8, "EBITDA_Growth_PCT", DoubleType(), required=False),
NestedField(9, "EBIT_Growth_PCT", DoubleType(), required=False),
NestedField(10, "EPS_Diluted_Growth_PCT", DoubleType(), required=False),
NestedField(11, "EPS_Growth_PCT", DoubleType(), required=False),
NestedField(12, "Cash_Conversion_Cycle", DoubleType(), required=False),
NestedField(13, "Cash_Per_Share", DoubleType(), required=False),
NestedField(14, "Current_Ratio", DoubleType(), required=False),
NestedField(15, "Debt_To_Equity", DoubleType(), required=False),
NestedField(16, "Debt_To_Asset", DoubleType(), required=False),
NestedField(17, "Debt_To_EBITDA", DoubleType(), required=False),
NestedField(18, "Debt_To_EBIT", DoubleType(), required=False),
NestedField(19, "Debt_To_Operating_CashFlow", DoubleType(), required=False),
NestedField(20, "Debt_To_Revenue", DoubleType(), required=False),
NestedField(21, "Debt_To_Shareholders_Equity", DoubleType(), required=False),
NestedField(22, "Equity_To_Asset", DoubleType(), required=False),
NestedField(23, "Five_Year_Dividend_Per_Share_Growth", DoubleType(), required=False),
NestedField(24, "Five_Year_Net_Income_Growth_Per_Share", DoubleType(), required=False),
NestedField(25, "Five_Year_Operating_CashFlow_Growth_Per_Share", DoubleType(), required=False),
NestedField(26, "Five_Year_Revenue_Growth_Per_Share", DoubleType(), required=False),
NestedField(27, "Five_Year_Shareholders_Equity_Growth_Per_Share", DoubleType(), required=False),
NestedField(28, "Free_CashFlow_Growth_PCT", DoubleType(), required=False),
NestedField(29, "Free_CashFlow_Per_Share", DoubleType(), required=False),
NestedField(30, "Gross_Profit_Growth_PCT", DoubleType(), required=False),
NestedField(31, "Gross_Profit_Margin", DoubleType(), required=False),
NestedField(32, "Inventory_Growth_PCT", DoubleType(), required=False),
NestedField(33, "Net_Income_Growth_PCT", DoubleType(), required=False),
NestedField(34, "Net_Income_Per_Share", DoubleType(), required=False),
NestedField(35, "Operating_CashFlow_Growth_PCT", DoubleType(), required=False),
NestedField(36, "Operating_CashFlow_Per_Share", DoubleType(), required=False),
NestedField(37, "Operating_Income_Growth_PCT", DoubleType(), required=False),
NestedField(38, "Revenue_Growth_PCT", DoubleType(), required=False),
NestedField(39, "RD_Expense_Growth_PCT", DoubleType(), required=False),
NestedField(40, "Period", StringType(), required=False),
NestedField(41, "Receivables_Growth_PCT", DoubleType(), required=False),
NestedField(42, "Receivables_Turnover", DoubleType(), required=False),
NestedField(43, "SGA_Expense_Growth_PCT", DoubleType(), required=False),
NestedField(44, "Three_Year_Shareholders_Equity_Growth_Per_Share", DoubleType(), required=False),
NestedField(45, "Three_Year_Revenue_Growth_Per_Share", DoubleType(), required=False),
NestedField(46, "Three_Year_Operating_CashFlow_Growth_Per_Share", DoubleType(), required=False),
NestedField(47, "Three_Year_Net_Income_Growth_Per_Share", DoubleType(), required=False ),
NestedField(48, "Three_Year_Dividend_Per_Share_Growth", DoubleType(), required=False),
NestedField(49, "Ten_Year_Shareholders_Equity_Growth_Per_Share", DoubleType(), required=False),
NestedField(50, "Ten_Year_Revenue_Growth_Per_Share", DoubleType(), required=False),
NestedField(51, "Ten_Year_Operating_CashFlow_Growth_Per_Share", DoubleType(), required=False),
NestedField(52, "Ten_Year_Net_Income_Growth_Per_Share", DoubleType(), required=False),
NestedField(53, "Ten_Year_Dividend_Per_Share_Growth", DoubleType(), required=False)
))
create_or_refresh_schema.py
from get_catalog import get_catalog
from schema_def import company_schema, ratio_schema_ttm, forecast_schema
catalog = get_catalog()
# schema list contains each schema definitions
schema_list = [company_schema, ratio_schema_ttm, forecast_schema]
table_list = ["company", "ratios_ttm", "forecasts"]
try:
for schema, tab in zip(schema_list, table_list):
catalog.drop_table(identifier=f"docs.{tab}")
print(f"Dropped table: docs.{tab}")
catalog.create_table_if_not_exists(identifier=f"docs.{tab}", schema=schema)
print(f"Created table: docs.{tab}")
except Exception as e:
print(e)
Up to this point everything was pretty straight forward, the next part was to load data into the tables. As I mentioned above, I was extracting my three datasets in pipe-delimited format from my Couchbase warehouse. I had three tables, but the "forecasts" table was larger and had records per calendar year, so I created a file per year for that table to keep the number of rows down. Just to make smaller "chunks" in the load instead of one large chunk.
I also had another nuance, in that the SQL++ queries did not exactly give me the column order as specified in the "SELECT" statement, so the columns in the file could be in a different order than in the schema definition. The driver is supplied by DataGrip and it still needs some refining to fix a few things. I needed to correct the column order on the load.
I decided to initially use Pandas dataframe for the initial table object, since it's interfaces are fairly stable, and column typing is easy to update. Plus, you can create a PyArrow table directly from a dataframe using the "from_pandas()" function, so switching formats was easy.
If you have very large datasets, and need more scalability, you could substitute DASK dataframes instead to read the file content into multiple partitions. Then loop through the DASK dataframe partitions -> convert using DASK to_pandas() -> convert using pyarrow from_pandas() to PyArrow. Otherwise you will need to read file content into numpy or arrow arrays in Python and create manipulate the data in the arrays. There is a use case for that, but my example was trying to be simple initially. If your using Java, arraylists would be feasible, but if you're using Apache Spark there is an extension for Iceberg.
So just to summarize, the load script needed to:
Read the pipe-delimited and double-quoted files
Re-order the columns in the file to match the already defined schema in Iceberg
Create a pandas dataframe from the data in #2
Apply type conversions for columns to match the target schema in Iceberg
Convert the pandas dataframe to a pyarrow table
Write the data to Iceberg
I will walk through the six points above in the order that they appear in the script, so I can provide more detail on what I did to address them. Below is a screenshot from Pycharm that gives you the imports, Pandas display options to help with viewing data, and two lists of target tables and data files. Since I had multiple data files for the "docs.forecasts" table, I just repeated the table name so I could iterate by zipping the two lists.
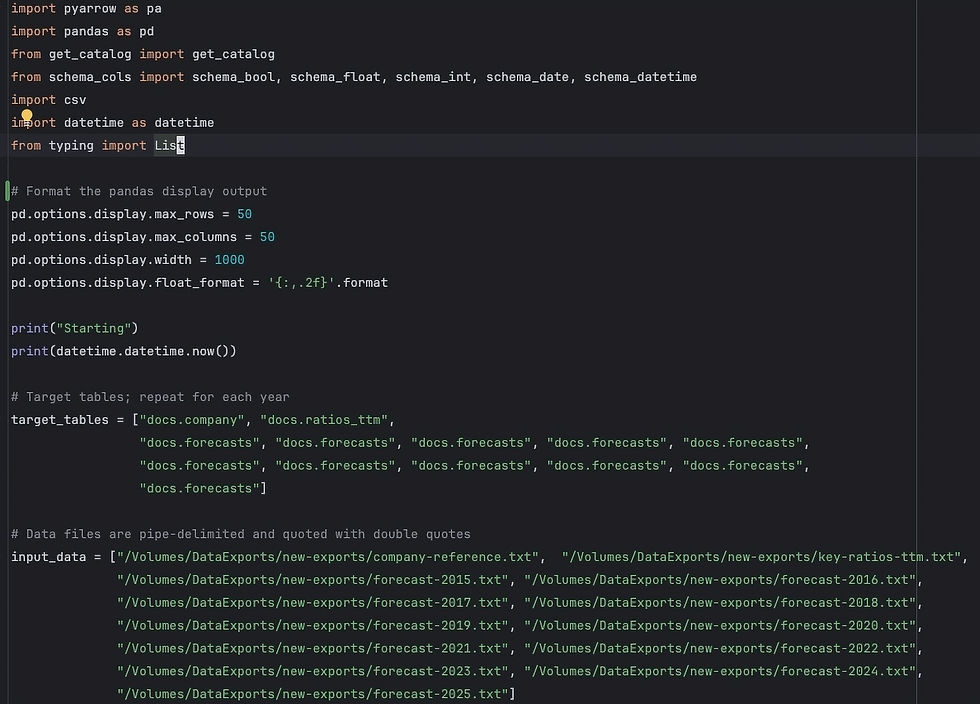
Next in the script is column typing (#4 in the list), and I decided to do this by creating a second script that would classify columns. For columns in each of the three tables, they were added to lists grouped together by type. Then have a function to call/return the types.

They are loaded by the load_data.py as below:

The column typing needs to a) be a supported Pandas type and b) one which PyArrow will convert to a valid type that matches the schema.
This turned into a slightly more cumbersome exercise that I wanted it to, so I would advise to cut-out the Pandas dataframe load and start directly with loading data into the PyArrow table instead, and addressing conversion issues there.
The next portion of the load_schema.py script addresses points #1 and #2 from the list, as seen below. The created table schemas are retrieved and matched against the header from the file, and reordered. I kept consistent names, so I did not need to use a map, so it would be a simple match. Obviously you would need a map if they are different names. The fields match the table order and ensure you're only using the columns defined in the schema.

At this point the correctly ordered data is loaded into a Pandas dataframe and types applied using the schema column types retrieved near the start of the script

The initial typing in this case, when the Pandas dataframe is created, is for all columns to be created as "objects" even trying "coerce". I created this section to iterate through the columns in the dataframe and check each one against each of the lists returned from the function, and set the type when matching. Not all columns are in the lists that are returned, just those that need typing changes. Columns that can remain an "object", i.e. string, just pass through the loop and remain the same. Finally I do a "fillna()" function on the Pandas dataframe to get rid of nan values.
The final section of the script is a bit of an anti-climax, due to it's simplicity.
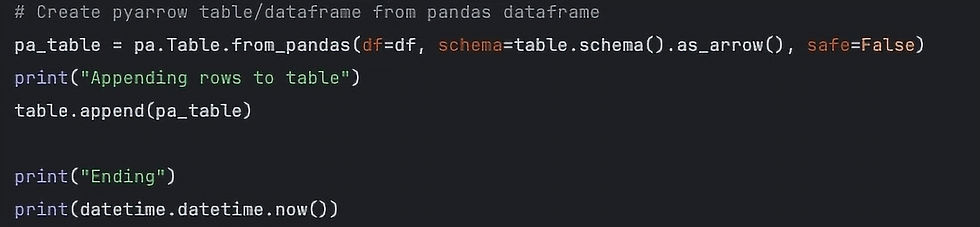
The conversion is fairly straight forward, and then its just appending the data to the table. This would be for an incremental or initial load, if you need to recon and replace data there are other methods you will need to employ. I will cover one method in the next posts in the blog series here.
I am going to have a Part III to this article to cover retrieving and aggregating the data with Pandas, since Part II ran longer than I expected. Below I added a few commands from the Python console, that you can use to see the Iceberg tables.










