Comprendre les distinctions entre la modélisation dimensionnelle et normalisée des données avec des exemples pratiques
- Claude Paugh

- 9 août 2025
- 5 min de lecture
La modélisation des données joue un rôle essentiel dans la conception et la gestion des bases de données des organisations. Elle façonne le stockage, la récupération et l'analyse des données. Deux approches principales dominent ce domaine : la modélisation dimensionnelle des données et la modélisation normalisée des données. Chaque méthode possède ses propres atouts et cas d'utilisation, ce qui la rend adaptée à différents types d'applications. Dans cet article, nous détaillerons les différences entre ces deux techniques de modélisation et fournirons des exemples pratiques pour illustrer clairement leurs applications.

Qu'est-ce que la modélisation des données dimensionnelles ?
La modélisation dimensionnelle des données est souvent utilisée dans l'entreposage de données et la veille stratégique. Cette approche vise à faciliter la récupération des données à des fins d'analyse. Son objectif principal est de créer une structure conviviale permettant un accès rapide aux informations.
Principales caractéristiques de la modélisation des données dimensionnelles
Schéma en étoile : L'un des modèles les plus populaires en modélisation dimensionnelle est le schéma en étoile. Ce modèle comporte une table de faits centrale entourée de tables de dimensions. La table de faits contient des données quantitatives, comme le chiffre d'affaires, tandis que les tables de dimensions fournissent un contexte supplémentaire (type de produit, périodes et informations client).
Dénormalisation : Dans les modèles dimensionnels, les données sont souvent dénormalisées. Cela signifie qu'elles peuvent être dupliquées entre les tables pour accélérer les requêtes. Par exemple, les détails d'un produit peuvent apparaître à la fois dans sa table de dimension et dans la table de faits.
Convivialité : Ces modèles sont conçus pour être intuitifs. Les utilisateurs professionnels, même sans connaissances techniques, peuvent facilement générer des rapports et tirer des conclusions sans formation approfondie.
Exemple de modélisation de données dimensionnelles
Imaginez un magasin de détail désireux d'analyser ses performances de vente. Un modèle dimensionnel pourrait ressembler à ceci :
Tableau des faits : « Ventes »
- Colonnes : `Sale_ID`, `Product_ID`, `Customer_ID`, `Calendar_ID`, `Product_Sale_Units`, `Product_Sale_USD`
Tableaux de dimensions :
- `Produit`
- Colonnes : `Product_ID`, `Product_Name`, `Category`, `Price`
- `Client`
- Colonnes : `Customer_ID`, `Customer_Name`, `Region`, `Age_Group`
- `Calendrier`
- Colonnes : `Calendar_dim_SID`, `Date`, `Mois`, `Année`, `Jour_du_mois`, `Numéro_jour_de_l'année`

Par exemple, la table de faits « Ventes » capture toutes les transactions. Les tables de dimensions « Produit », « Client » et « Calendrier » ajoutent du contexte, permettant aux utilisateurs d'explorer des questions telles que « Quel a été le total des ventes pour chaque catégorie en 2023 ? »
Qu'est-ce que la modélisation de données normalisées ?
La modélisation normalisée des données est structurée de manière à minimiser la redondance des données et à garantir leur intégrité. On la retrouve couramment dans les bases de données transactionnelles, où une gestion efficace des données est essentielle.
Principales caractéristiques de la modélisation de données normalisées
Normalisation : Ce processus organise les données en tables liées afin de réduire les doublons. Chaque table représente généralement une entité. Les relations entre les tables sont maintenues par des clés étrangères, garantissant clarté et cohérence.
Requêtes complexes : si les modèles normalisés permettent d'éliminer la redondance, ils génèrent souvent des requêtes plus complexes nécessitant plusieurs jointures pour la récupération des données. Dans les bases de données volumineuses, cela peut parfois ralentir les performances.
Intégrité des données : La normalisation contribue à l'exactitude et à la cohérence des données. Ainsi, lors des mises à jour, des suppressions ou des nouvelles entrées, l'intégrité des données est préservée, évitant ainsi les erreurs.
Exemple de modélisation de données normalisées
En utilisant le même scénario de vente au détail, le modèle normalisé pourrait ressembler à ceci :
Tableau : « Ventes »
- Colonnes : `Sale_ID`, `Product_ID`, `Customer_ID`, `Calendar_ID`, `Quantity_Sold`, `Total_Sale`
Tableau : « Produit »
- Colonnes : `Product_ID`, `Product_Name`, `Category_ID`, `Price`
Tableau : « Catégorie »
- Colonnes : `Category_ID`, `Category_Name`
Tableau : « Client »
- Colonnes : `Customer_ID`, `Customer_Name`, `Region_ID`
Tableau : « Région »
- Colonnes : `Region_ID`, `Region_Name`
Tableau : « Calendrier »
- Colonnes : `Calendar_ID`, `Date_ID`, `Month`, `Year`
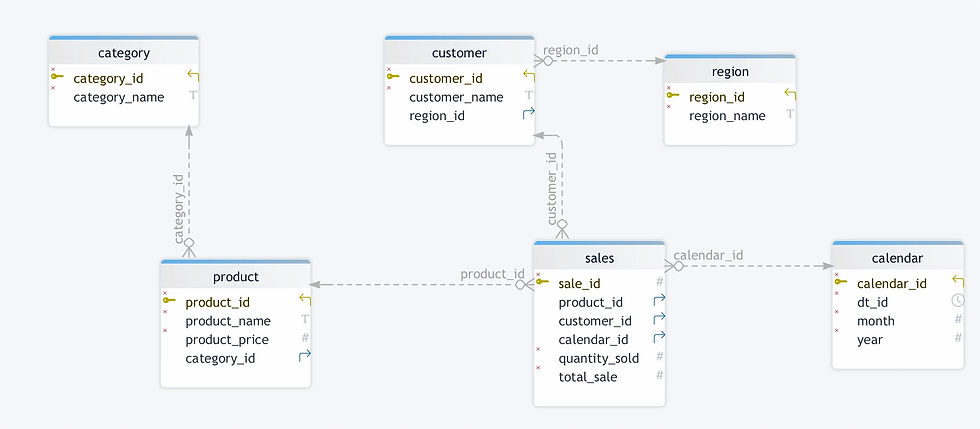
Dans cet exemple, la table « Produit » est connectée à une table « Catégorie » distincte, permettant une gestion complète des données avec moins de doublons. Cependant, les requêtes peuvent nécessiter davantage de jointures pour relier efficacement les informations.
Comparaison de la modélisation des données dimensionnelles et normalisées
Objectif et cas d'utilisation
Modélisation dimensionnelle des données : Cette approche est particulièrement efficace dans les scénarios analytiques, notamment en entrepôt de données et en veille stratégique. Sa conception vise à accélérer les requêtes et à simplifier l'accès pour les utilisateurs.
Modélisation normalisée des données : cette méthode est particulièrement adaptée aux systèmes transactionnels, où l'accent est mis sur l'intégrité des données et la minimisation de la redondance. Elle est couramment utilisée dans les bases de données opérationnelles soumises à des mises à jour fréquentes.
Performance
Modèles dimensionnels : ils offrent généralement de meilleures performances pour les opérations de lecture intensive, car ils réduisent le nombre de jointures de tables nécessaires à la récupération des données.
Modèles normalisés : bien que ces modèles puissent connaître des performances lentes pour les opérations de lecture en raison de plusieurs jointures, ils excellent dans le maintien de l’intégrité et de la vitesse des données pendant les opérations d’écriture.
Complexité
Modèles dimensionnels : ils sont généralement plus simples et plus conviviaux. Ils permettent aux utilisateurs non techniques de générer des analyses et des rapports sans trop de difficultés.
Modèles normalisés : ils peuvent être complexes en raison des relations entre les tables, ce qui rend la navigation difficile pour les utilisateurs qui manquent d'expertise technique.
Quand utiliser chaque modèle
Quand choisir la modélisation des données dimensionnelles
Besoins en Business Intelligence : Si votre organisation s’appuie fortement sur l’analyse et le reporting, un modèle dimensionnel est idéal.
Accès convivial : lorsque les utilisateurs cibles ne sont pas techniques et que vous souhaitez qu'ils accèdent aux données facilement et efficacement.
Performances de requête élevées : si votre application nécessite des réponses de requête rapides, la modélisation dimensionnelle est le bon choix, en particulier pour les ensembles de données plus volumineux.
Quand choisir la modélisation de données normalisées
Systèmes transactionnels : si le maintien de l’intégrité des données et la minimisation de la redondance sont vos principales priorités.
Mises à jour fréquentes : les modèles normalisés sont utiles lorsque votre application traite fréquemment des mises à jour, des suppressions ou de nouvelles entrées.
Relations complexes : si vos données incluent des relations complexes qui nécessitent une gestion minutieuse, la normalisation permet de les structurer efficacement.
Réflexions finales
Comprendre les différences entre la modélisation dimensionnelle et la modélisation normalisée des données est essentiel pour les organisations souhaitant affiner leurs stratégies de gestion des données. La modélisation dimensionnelle s'avère bénéfique dans les contextes analytiques en permettant un accès convivial et des requêtes plus rapides. À l'inverse, la modélisation normalisée prend en charge les environnements transactionnels en garantissant l'intégrité des données et en minimisant la redondance.
Tenez compte des besoins spécifiques de votre organisation et des caractéristiques de vos données pour déterminer la meilleure approche de modélisation. Utiliser le bon modèle de données peut considérablement optimiser la gestion des données et la prise de décision.

En résumé, la modélisation dimensionnelle et la modélisation normalisée des données présentent des caractéristiques uniques. Le choix entre ces deux approches doit s'adapter aux exigences de votre environnement de données et aux compétences techniques de votre équipe. Avec le bon modèle en place, les organisations peuvent améliorer leurs pratiques en matière de données et favoriser une meilleure prise de décision.
