実例を用いて、次元データモデリングと正規化データモデリングの違いを理解する
- Claude Paugh

- 2025年8月9日
- 読了時間: 7分
データモデリングは、組織がデータベースを設計・管理する上で重要な役割を果たします。データの保存、取得、分析方法を形作るからです。この分野では、主に2つのアプローチ、すなわち多次元データモデリングと正規化データモデリングが主流です。それぞれの手法には独自の長所とユースケースがあり、異なる種類のアプリケーションに適しています。この記事では、これら2つのモデリング手法の違いを詳しく説明し、具体的な例を挙げて、それぞれの適用例を分かりやすく説明します。

ディメンション データ モデリングとは何ですか?
次元データモデリングは、データウェアハウスやビジネスインテリジェンスでよく用いられます。このアプローチは、分析のためにデータを容易に取得できるようにすることに重点を置いています。その本質は、ユーザーフレンドリーな構造を構築し、洞察に素早くアクセスできるようにすることです。
次元データモデリングの主な特徴
スタースキーマ:ディメンションモデリングにおいて最も一般的なレイアウトの一つがスタースキーマです。このモデルは、中心となるファクトテーブルとその周囲を囲むディメンションテーブルで構成されています。ファクトテーブルには売上高などの定量データが保持され、ディメンションテーブルには製品タイプ、期間、顧客情報などの追加コンテキストが提供されます。
非正規化:ディメンションモデルでは、データが非正規化されることがよくあります。これは、クエリのパフォーマンスを向上させるために、データが複数のテーブルに複製されることを意味します。例えば、製品の詳細がディメンションテーブルとファクトテーブルの両方に表示される場合があります。
ユーザーフレンドリー:これらのモデルは直感的に操作できるように設計されています。技術に詳しくないビジネスユーザーでも、特別なトレーニングを受けることなく、簡単にレポートを作成し、洞察を得ることができます。
次元データモデリングの例
販売実績の分析に熱心な小売店を想像してみてください。次元モデルは次のようになります。
ファクトテーブル: `売上`
- 列: `Sale_ID`、`Product_ID`、`Customer_ID`、`Calendar_ID`、`Product_Sale_Units`、`Product_Sale_USD`
ディメンションテーブル:
- 「製品」
- 列: `Product_ID`、`Product_Name`、`Category`、`Price`
- 「顧客」
- 列: `Customer_ID`、`Customer_Name`、`Region`、`Age_Group`
- `カレンダー`
- 列: `Calendar_dim_SID`、`Date`、`Month`、`Year`、`Day_of_Month`、`Day_num_of_year`

例えば、「売上」ファクトテーブルはすべての取引をキャプチャします。一方、「製品」、「顧客」、「カレンダー」ディメンションテーブルはコンテキストを追加し、「2023年の各カテゴリの総売上高はいくらだったか」といった質問を分析できます。
正規化データモデリングとは何ですか?
正規化データモデリングは、データの冗長性を最小限に抑え、データの整合性を確保するように構造化されています。効率的なデータ管理が重要となるトランザクションデータベースでよく見られます。
正規化データモデリングの主な特徴
正規化:このプロセスでは、データの重複を減らすために、関連するテーブルにデータを整理します。各テーブルは通常、1つのエンティティを表します。テーブル間の関係は外部キーによって維持され、明瞭性と一貫性が確保されます。
複雑なクエリ:正規化されたモデルは冗長性を排除するのに役立ちますが、多くの場合、データ取得に複数の結合を必要とする複雑なクエリにつながります。大規模なデータベースでは、パフォーマンスが低下する可能性があります。
データの整合性:正規化は、データの正確性と一貫性を維持するのに役立ちます。つまり、更新、削除、または新規エントリの実行時にデータの整合性が維持され、エラーを防止します。
正規化データモデリングの例
同じ小売ビジネス シナリオを使用すると、正規化されたモデルは次のようになります。
表: `売上`
- 列: `Sale_ID`、`Product_ID`、`Customer_ID`、`Calendar_ID`、`Quantity_Sold`、`Total_Sale`
テーブル: `Product`
- 列: `Product_ID`、`Product_Name`、`Category_ID`、`Price`
テーブル: `カテゴリ`
- 列: `Category_ID`、`Category_Name`
テーブル: `顧客`
- 列: `Customer_ID`、`Customer_Name`、`Region_ID`
テーブル: `地域`
- 列: `Region_ID`、`Region_Name`
テーブル: `カレンダー`
- 列: `Calendar_ID`、`Date_ID`、`Month`、`Year`
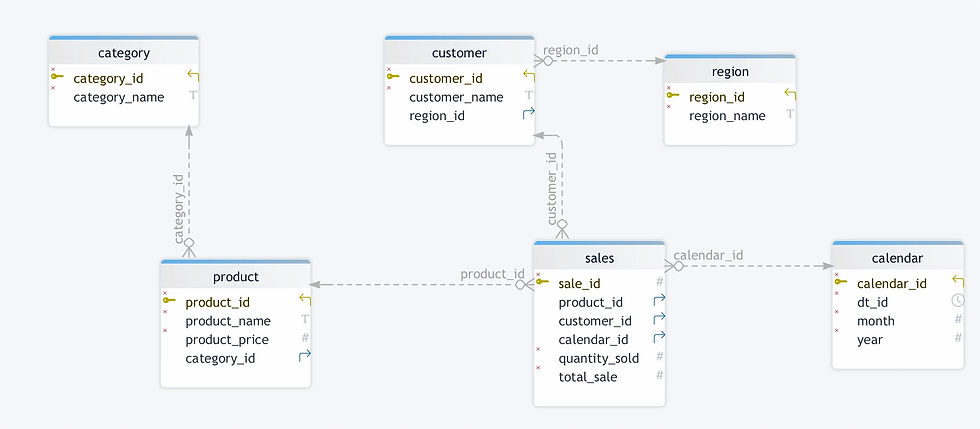
この例では、「Product」テーブルが別の「Category」テーブルに接続されており、重複を減らした包括的なデータ管理を実現しています。ただし、クエリでは情報を効果的に関連付けるために、より多くの結合が必要になる場合があります。
次元データモデリングと正規化データモデリングの比較
目的とユースケース
次元データモデリング:このアプローチは、特にデータウェアハウスやビジネスインテリジェンスといった分析シナリオで威力を発揮します。その設計は、高速なクエリパフォーマンスとユーザーにとっての容易なアクセスを目的としています。
正規化データモデリング:これは、データの整合性と冗長性の最小化に重点を置くトランザクションシステムに適しています。頻繁に更新される運用データベースでよく活用されます。
パフォーマンス
ディメンションモデル:ディメンションモデルは、通常、読み取り負荷の高い操作において優れたパフォーマンスを発揮します。これは、データ取得時に必要なテーブル結合の回数が削減されるためです。
正規化モデル: これらのモデルでは、複数の結合により読み取り操作のパフォーマンスが低下する可能性がありますが、書き込み操作中のデータの整合性と速度の維持には優れています。
複雑
ディメンションモデル:これらは一般的にシンプルでユーザーフレンドリーです。技術に詳しくないユーザーでも、簡単に分析情報やレポートを作成できます。
正規化モデル: テーブル間の関係により複雑になる可能性があり、技術的な専門知識がないユーザーにとってはナビゲーションが困難になります。
各モデルを使用するタイミング
ディメンションデータモデリングを選択するタイミング
ビジネス インテリジェンスのニーズ: 組織が分析とレポートに大きく依存している場合は、ディメンション モデルが最適です。
ユーザーフレンドリーなアクセス: 対象ユーザーが技術者でなく、データに簡単かつ効率的にアクセスできるようにしたい場合。
高いクエリ パフォーマンス: アプリケーションで高速なクエリ応答が必要な場合は、特に大規模なデータセットの場合は、ディメンション モデリングが適切な選択です。
正規化データモデリングを選択するタイミング
トランザクション システム: データの整合性を維持し、冗長性を最小限に抑えることが最優先事項である場合。
頻繁な更新: アプリケーションが更新、削除、または新しいエントリを頻繁に処理する場合、正規化されたモデルが役立ちます。
複雑な関係: データに慎重な管理が必要な複雑な関係が含まれている場合、正規化によってデータを効果的に構造化できます。
最後に
データ管理戦略の見直しを目指す組織にとって、ディメンション型データモデリングと正規化データモデリングの違いを理解することは不可欠です。ディメンション型モデリングは、ユーザーフレンドリーなアクセスと高速なクエリを可能にするため、分析環境において有益です。一方、正規化モデリングは、データの整合性を確保し、冗長性を最小限に抑えることで、トランザクション環境をサポートします。
組織固有のニーズとデータ特性を考慮して、最適なモデリング手法を決定してください。適切なデータモデルを活用することで、データ管理の効率を大幅に向上させ、意思決定能力を向上させることができます。

まとめると、ディメンション化データモデリングと正規化データモデリングはそれぞれ独自の特性を持っています。どちらを選択するかは、データ環境の要件とチームの技術的能力に応じて決定する必要があります。適切なモデルを導入することで、組織はデータ活用を強化し、より優れた意思決定を促進できます。
