Die Unterschiede zwischen dimensionaler und normalisierter Datenmodellierung anhand praktischer Beispiele verstehen
- Claude Paugh

- 9. Aug. 2025
- 4 Min. Lesezeit
Datenmodellierung spielt eine entscheidende Rolle bei der Gestaltung und Verwaltung von Datenbanken in Unternehmen. Sie beeinflusst, wie Daten gespeichert, abgerufen und analysiert werden. Zwei primäre Ansätze dominieren dieses Feld: dimensionale Datenmodellierung und normalisierte Datenmodellierung. Jede Methode hat ihre eigenen Stärken und Anwendungsfälle und eignet sich daher für unterschiedliche Anwendungsbereiche. In diesem Beitrag erläutern wir die Unterschiede zwischen diesen beiden Modellierungstechniken und veranschaulichen ihre Anwendung anhand praktischer Beispiele.

Was ist dimensionale Datenmodellierung?
Die dimensionale Datenmodellierung wird häufig im Data Warehousing und in der Business Intelligence eingesetzt. Bei diesem Ansatz steht die einfache Datenabfrage für Analysen im Vordergrund. Im Kern geht es darum, eine benutzerfreundliche Struktur zu schaffen, die einen schnellen Zugriff auf Erkenntnisse ermöglicht.
Hauptmerkmale der dimensionalen Datenmodellierung
Sternschema : Eines der beliebtesten Layouts in der Dimensionsmodellierung ist das Sternschema. Dieses Modell besteht aus einer zentralen Faktentabelle, die von Dimensionstabellen umgeben ist. Die Faktentabelle enthält quantitative Daten – wie beispielsweise den Umsatz –, während die Dimensionstabellen zusätzlichen Kontext liefern (wie Produkttyp, Zeiträume und Kundendetails).
Denormalisierung : In dimensionalen Modellen werden Daten häufig denormalisiert. Das bedeutet, dass Daten in mehreren Tabellen dupliziert werden können, um die Abfrageleistung zu verbessern. Beispielsweise können die Details eines Produkts sowohl in der Dimensionstabelle als auch in der Faktentabelle erscheinen.
Benutzerfreundlich : Diese Modelle sind intuitiv gestaltet. Auch technisch nicht versierte Geschäftsanwender können ohne umfangreiche Schulung problemlos Berichte erstellen und Erkenntnisse gewinnen.
Beispiel für dimensionale Datenmodellierung
Stellen Sie sich ein Einzelhandelsgeschäft vor, das seine Verkaufszahlen analysieren möchte. Ein dimensionales Modell könnte folgendermaßen aussehen:
Faktentabelle : „Verkäufe“
- Spalten: `Sale_ID`, `Product_ID`, `Customer_ID`, `Calendar_ID`, `Product_Sale_Units`, `Product_Sale_USD`
Dimensionstabellen :
- `Produkt`
- Spalten: `Product_ID`, `Product_Name`, `Category`, `Price`
- `Kunde`
- Spalten: „Kunden-ID“, „Kundenname“, „Region“, „Altersgruppe“
- `Kalender`
- Spalten: `Calendar_dim_SID`, `Datum`, `Monat`, `Jahr`, `Tag_des_Monats`, `Tag_Nummer_des_Jahres`

Beispielsweise erfasst die Faktentabelle „Umsatz“ alle Transaktionen. Die Dimensionstabellen „Produkt“, „Kunde“ und „Kalender“ fügen Kontext hinzu und ermöglichen Benutzern die Untersuchung von Fragen wie „Wie hoch waren die Gesamtumsätze für jede Kategorie im Jahr 2023?“
Was ist normalisierte Datenmodellierung?
Die normalisierte Datenmodellierung ist so strukturiert, dass Datenredundanz minimiert und die Datenintegrität gewährleistet wird. Sie wird häufig in Transaktionsdatenbanken eingesetzt, bei denen effizientes Datenmanagement entscheidend ist.
Hauptmerkmale der normalisierten Datenmodellierung
Normalisierung : Dieser Prozess organisiert Daten in verknüpften Tabellen, um Duplikate zu vermeiden. Jede Tabelle stellt typischerweise eine Entität dar. Die Beziehungen zwischen den Tabellen werden durch Fremdschlüssel aufrechterhalten, um Klarheit und Konsistenz zu gewährleisten.
Komplexe Abfragen : Normalisierte Modelle tragen zwar zur Vermeidung von Redundanz bei, führen aber oft zu komplexeren Abfragen, die mehrere Verknüpfungen zum Datenabruf erfordern. Bei größeren Datenbanken kann dies die Leistung beeinträchtigen.
Datenintegrität : Durch Normalisierung bleiben die Daten genau und konsistent. Dies bedeutet, dass bei Aktualisierungen, Löschungen oder neuen Einträgen die Datenintegrität gewahrt bleibt und Fehler vermieden werden.
Beispiel für normalisierte Datenmodellierung
Bei Verwendung desselben Einzelhandelsgeschäftsszenarios könnte das normalisierte Modell folgendermaßen aussehen:
Tabelle: `Umsatz`
- Spalten: `Sale_ID`, `Product_ID`, `Customer_ID`, `Calendar_ID`, `Quantity_Sold`, `Total_Sale`
Tabelle: `Produkt`
- Spalten: `Product_ID`, `Product_Name`, `Category_ID`, `Preis`
Tabelle: `Kategorie`
- Spalten: `Category_ID`, `Category_Name`
Tabelle: `Kunde`
- Spalten: „Customer_ID“, „Customer_Name“, „Region_ID“
Tabelle: `Region`
- Spalten: `Region_ID`, `Region_Name`
Tabelle: `Kalender`
- Spalten: `Kalender-ID`, `Datums-ID`, `Monat`, `Jahr`
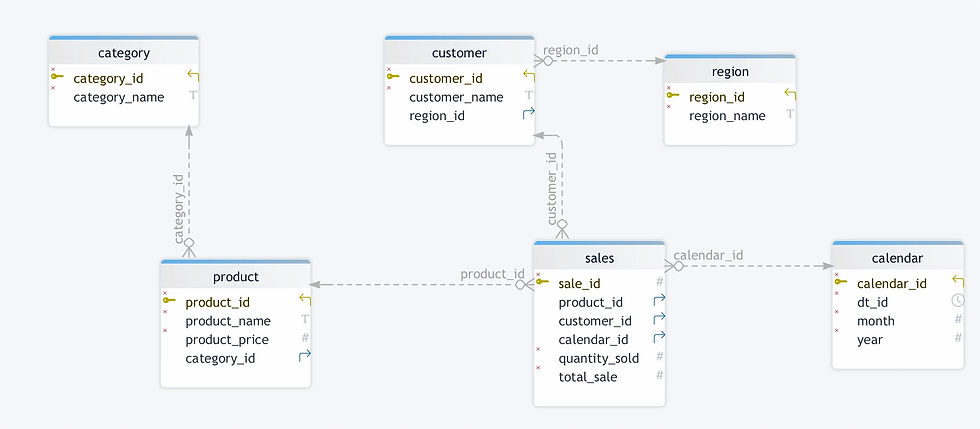
In diesem Beispiel ist die Tabelle „Produkt“ mit einer separaten Tabelle „Kategorie“ verknüpft. Dies ermöglicht eine umfassende Datenverwaltung mit weniger Duplikaten. Abfragen erfordern jedoch möglicherweise mehr Verknüpfungen, um die Informationen effektiv zu verknüpfen.
Vergleich dimensionaler und normalisierter Datenmodellierung
Zweck und Anwendungsfälle
Dimensionale Datenmodellierung : Dieser Ansatz eignet sich hervorragend für analytische Szenarien, insbesondere im Data Warehousing und in der Business Intelligence. Sein Design zielt auf schnelle Abfrageleistung und einfachen Zugriff für Benutzer ab.
Normalisierte Datenmodellierung : Diese Methode eignet sich besser für Transaktionssysteme, bei denen der Schwerpunkt auf Datenintegrität und Redundanzminimierung liegt. Sie wird häufig in operativen Datenbanken eingesetzt, die häufig aktualisiert werden.
Leistung
Dimensionale Modelle : Sie bieten in der Regel eine bessere Leistung bei leseintensiven Vorgängen. Dies liegt daran, dass sie die Anzahl der beim Datenabruf erforderlichen Tabellenverknüpfungen reduzieren.
Normalisierte Modelle : Bei diesen Modellen kann es aufgrund mehrerer Verknüpfungen zu einer langsamen Leistung bei Lesevorgängen kommen, sie zeichnen sich jedoch durch die Aufrechterhaltung der Datenintegrität und Geschwindigkeit bei Schreibvorgängen aus.
Komplexität
Dimensionale Modelle : Diese sind im Allgemeinen einfacher und benutzerfreundlicher. Sie ermöglichen es auch nicht-technischen Benutzern, ohne große Schwierigkeiten Erkenntnisse und Berichte zu generieren.
Normalisierte Modelle : Diese können aufgrund der Beziehungen zwischen den Tabellen komplex sein, was die Navigation für Benutzer ohne technisches Fachwissen zu einer Herausforderung macht.
Wann welches Modell verwendet werden soll
Wann ist die dimensionale Datenmodellierung sinnvoll?
Business Intelligence-Anforderungen : Wenn Ihr Unternehmen stark auf Analysen und Berichte angewiesen ist, ist ein dimensionales Modell ideal.
Benutzerfreundlicher Zugriff : Wenn die Zielbenutzer keine technischen Kenntnisse haben und Sie möchten, dass sie einfach und effizient auf die Daten zugreifen.
Hohe Abfrageleistung : Wenn Ihre Anwendung schnelle Abfrageantworten erfordert, ist die dimensionale Modellierung die richtige Wahl, insbesondere für größere Datensätze.
Wann ist eine normalisierte Datenmodellierung sinnvoll?
Transaktionssysteme : Wenn die Aufrechterhaltung der Datenintegrität und die Minimierung von Redundanz Ihre obersten Prioritäten sind.
Häufige Aktualisierungen : Normalisierte Modelle sind von Vorteil, wenn Ihre Anwendung häufig Aktualisierungen, Löschungen oder neue Einträge verarbeitet.
Komplexe Beziehungen : Wenn Ihre Daten komplizierte Beziehungen enthalten, die sorgfältig verwaltet werden müssen, hilft die Normalisierung dabei, sie effektiv zu strukturieren.
Abschließende Gedanken
Für Unternehmen, die ihre Datenmanagementstrategien optimieren möchten, ist es wichtig, die Unterschiede zwischen dimensionaler und normalisierter Datenmodellierung zu verstehen. Die dimensionale Modellierung erweist sich in analytischen Kontexten als vorteilhaft, da sie benutzerfreundlichen Zugriff und schnellere Abfragen ermöglicht. Im Gegensatz dazu unterstützt die normalisierte Modellierung transaktionale Umgebungen, indem sie die Datenintegrität sicherstellt und Redundanz minimiert.
Berücksichtigen Sie die spezifischen Anforderungen und Datenmerkmale Ihres Unternehmens, um den optimalen Modellierungsansatz zu bestimmen. Die Nutzung des richtigen Datenmodells kann die Effizienz des Datenmanagements deutlich steigern und die Entscheidungsfindung verbessern.

Zusammenfassend lässt sich sagen, dass sowohl die dimensionale als auch die normalisierte Datenmodellierung einzigartige Eigenschaften haben. Die Wahl zwischen beiden sollte den Anforderungen Ihrer Datenumgebung und den technischen Fähigkeiten Ihres Teams entsprechen. Mit dem richtigen Modell können Unternehmen ihre Datenpraktiken verbessern und fundiertere Entscheidungen treffen.
